Inversión de campaña
€162.400
Anticipar y reducir la fuga de clientes en Elastic · prototipo entrenado con el dataset público Cell2Cell
Equipo · Julia Masvidal · Manuel Rivero · Rodrigo Careaga
Un modelo de churn no se optimiza por accuracy, se optimiza por DINERO. El proyecto recorre el ML Lifecycle completo y culmina en una curva de coste que fija el punto de operación.
Cifras del experimento sobre el dataset público Cell2Cell, no de datos reales de Elastic.
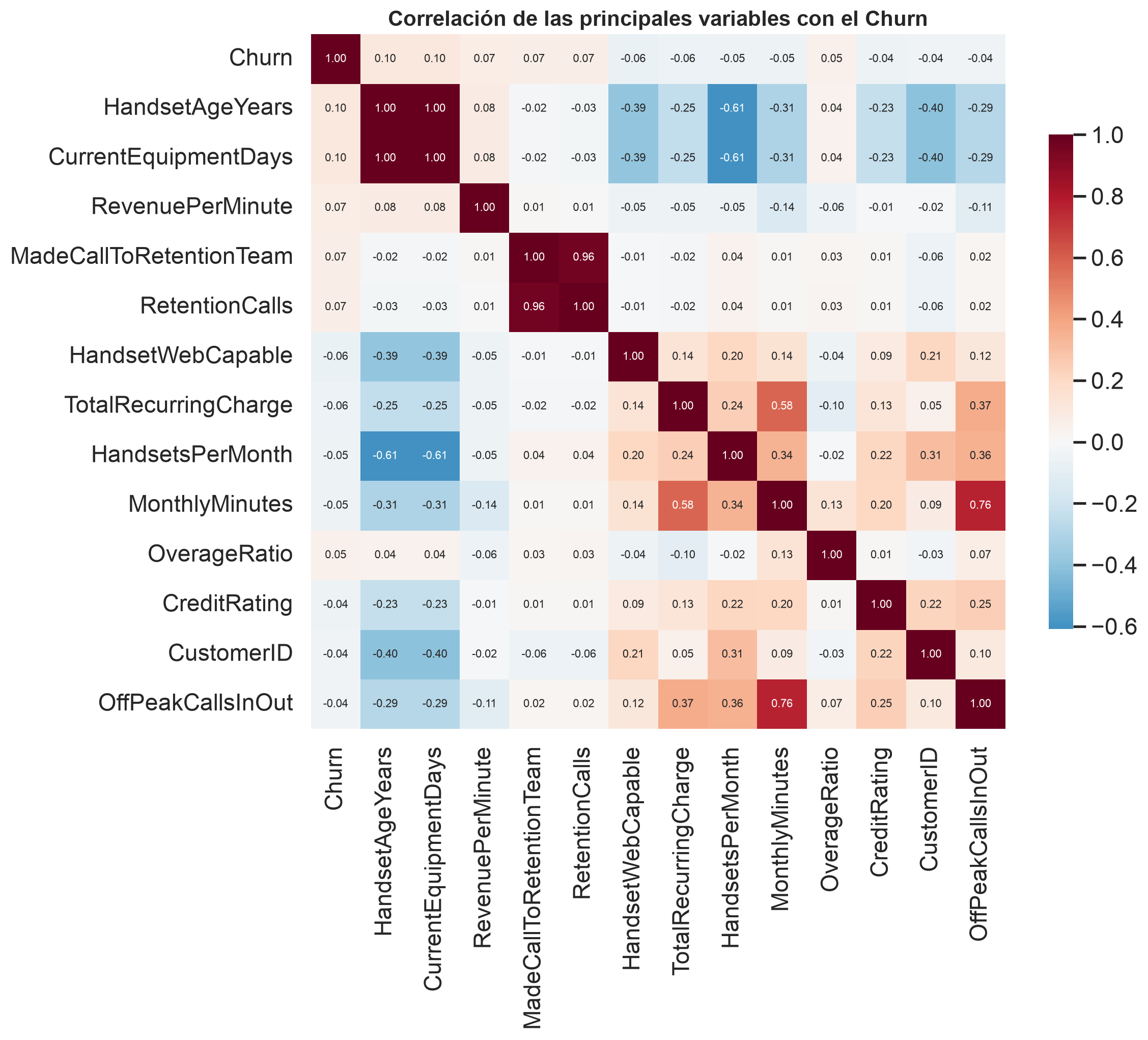
En Elastic — software de búsqueda, observabilidad y seguridad, con negocio de suscripción — el churn (la no-renovación de suscripciones) es uno de los problemas más graves: retener la base instalada gobierna el crecimiento (Net Revenue Retention). El presupuesto de retención es limitado, así que la pregunta no es técnica, es de negocio: ¿a qué cuentas en riesgo contactar para maximizar el ROI de retención?
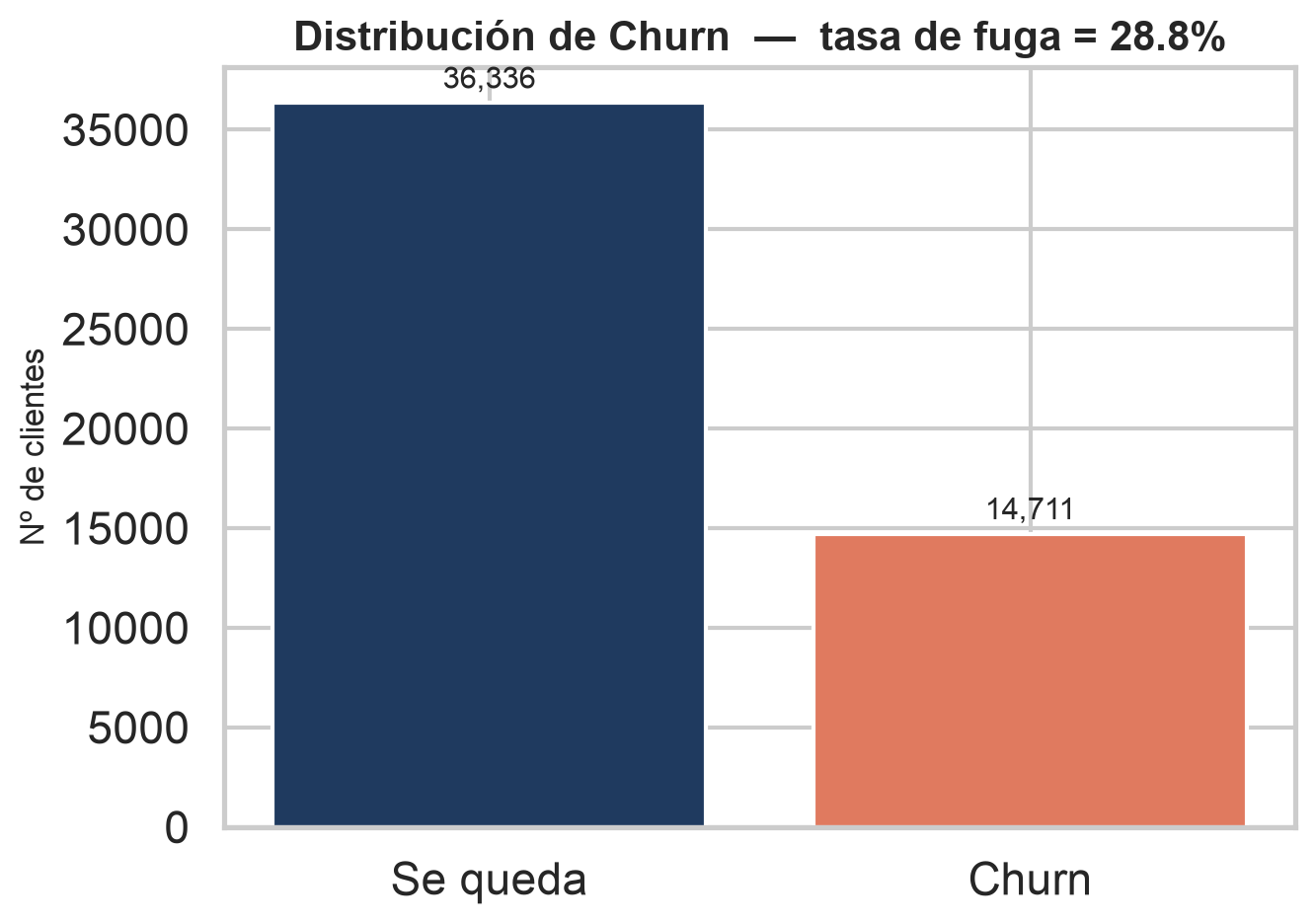
En el dataset de entrenamiento Cell2Cell la tasa de churn es del 28,8%. En un negocio de suscripción, cada cuenta perdida es ARR que se evapora y coste de readquisición para reemplazarla.
La retención tiene un coste por contacto y una bolsa acotada. Ofrecer un descuento a toda la base es derroche: se regala margen a quien nunca se iba a ir.
¿A quién contactar para maximizar el ROI de retención? Ese es el objetivo que gobierna todo el proyecto — no la métrica de moda.
Dataset público del sector telco (Cell2Cell), usado aquí como set de entrenamiento y validación. El split es estratificado para preservar la tasa de fuga, y toda la preparación se ajusta solo en train para evitar cualquier fuga de información.
El modelo se entrena y valida como prueba de concepto con el dataset público Cell2Cell (telco), ya que los datos reales de clientes de Elastic no son públicos. La metodología —feature engineering de comportamiento, modelo cost-sensitive, umbral por curva de coste y priorización— es directamente transferible al churn de suscripción de Elastic. Todas las cifras mostradas provienen del experimento sobre Cell2Cell, no de datos reales de Elastic.
Clientes etiquetados para entrenamiento
(cell2celltrain.csv · 58 columnas originales)
Clientes sin etiqueta de holdout
(cell2cellholdout.csv · el entregable)
Split estratificado 80/20 → train 40.837 / test 10.210, manteniendo el churn al 28,8% en ambos conjuntos.
Tras la preparación, 70 variables entran al modelo: 69 numéricas más codificación one-hot y frequency encoding. La imputación y el encoding se aprenden únicamente con los datos de entrenamiento mediante Pipeline + ColumnTransformer de scikit-learn.
El grueso del valor no está en el algoritmo, sino en la disciplina de datos que lo precede. Cerca del 80% del esfuerzo vive en la preparación.
Limpieza determinista sin data leakage. Imputación y encoding se ajustan solo en train con Pipeline + ColumnTransformer.
~80% del esfuerzo14 variables de negocio: ratios de comportamiento, tendencias y flags que capturan por qué un cliente se enfría.
6 de las 10 top5 modelos comparados en igualdad de condiciones, desde Naive Bayes hasta un FT-Transformer de deep learning.
5 modelosMétricas técnicas, curvas ROC e importancia de variables para entender la capacidad de discriminación real.
ROC · importanciaCurva de coste → umbral óptimo → ROI. Aquí el modelo se traduce en euros y en una lista accionable.
Coste → ROINo basta con las columnas del CRM. Traducir el comportamiento del cliente en señales de negocio (calidad, bill shock, tendencia, fricción, valor y equipo) es lo que dispara la señal predictiva.
DroppedCallRate, QualityIssueRate — un servicio que falla empuja al cliente a la puerta.
OverageRatio, RevenuePerMinute — pagar de más por lo mismo enciende la fuga.
DecliningUsage, PercChangeMinutes — el consumo que cae anticipa la baja.
CareCallsPerMonth — llamar mucho a atención al cliente es una señal de hartazgo.
TenureValueToDate, RevenuePerActiveSub, IsNewCustomer — cuánto vale y cuánto lleva.
HandsetAgeYears, HandsetsPerMonth — un terminal viejo es motivo clásico de cambio.
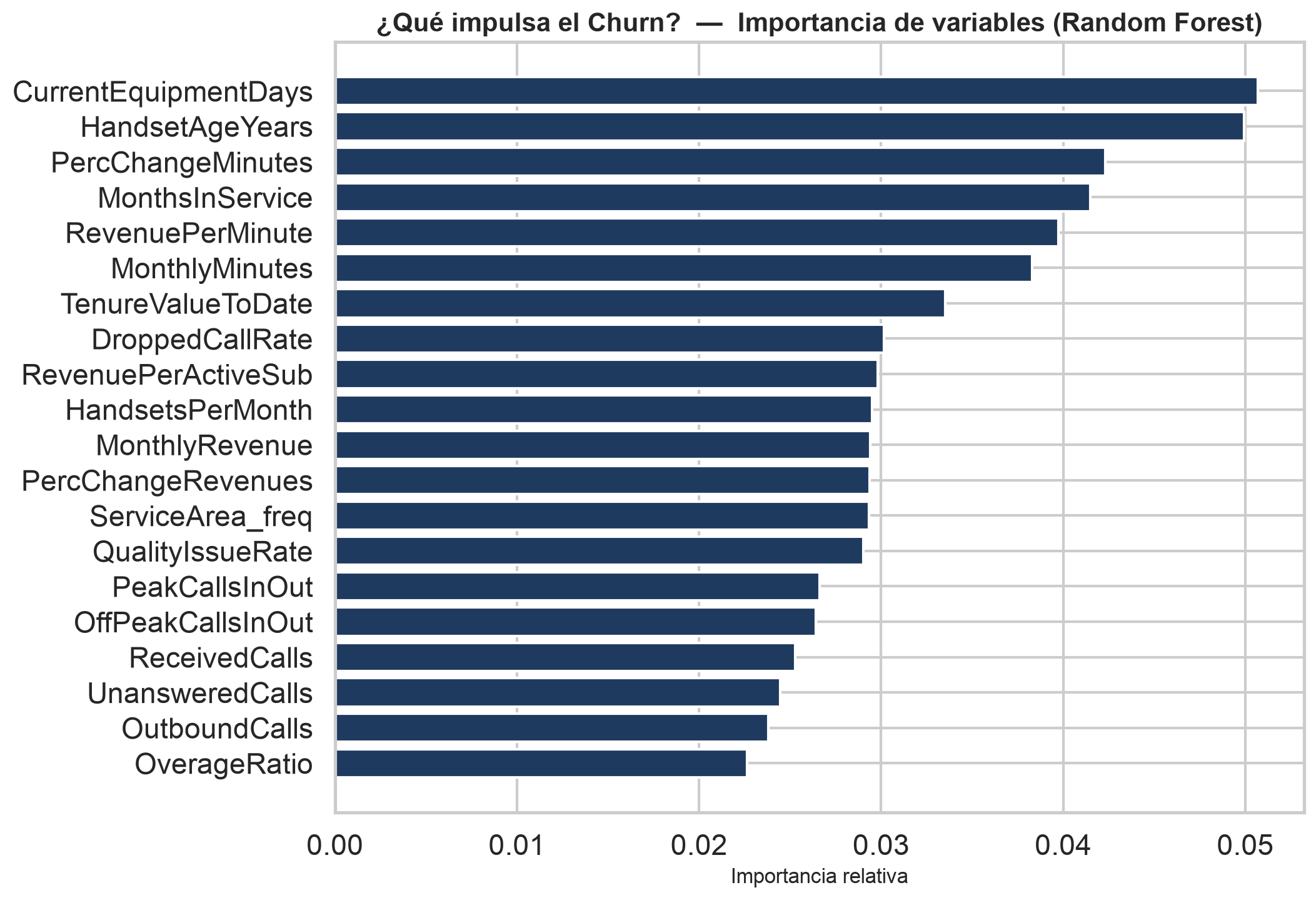
Top 10 variables por importancia
6 de las 10 variables más predictivas fueron diseñadas en feature engineering. El valor de negocio se construye, no viene dado en el CSV.
Las mismas familias de señales de comportamiento existen en un negocio de suscripción. La lógica del feature engineering es idéntica; solo cambia el origen del dato.
| Señal en Cell2Cell (telco) | Equivalente hipotético en Elastic (SaaS de suscripción) |
|---|---|
| Uso decreciente de minutos | Caída en datos ingeridos, consultas o logins (leading indicator) |
| Llamadas caídas / calidad de red | Incidentes, latencia o errores del servicio |
| Llamadas a soporte | Volumen y severidad de tickets de soporte |
| Antigüedad del terminal | Antigüedad/versión del despliegue, adopción de features |
| ARPU / valor por suscriptor | ARR por cuenta, expansión de asientos |
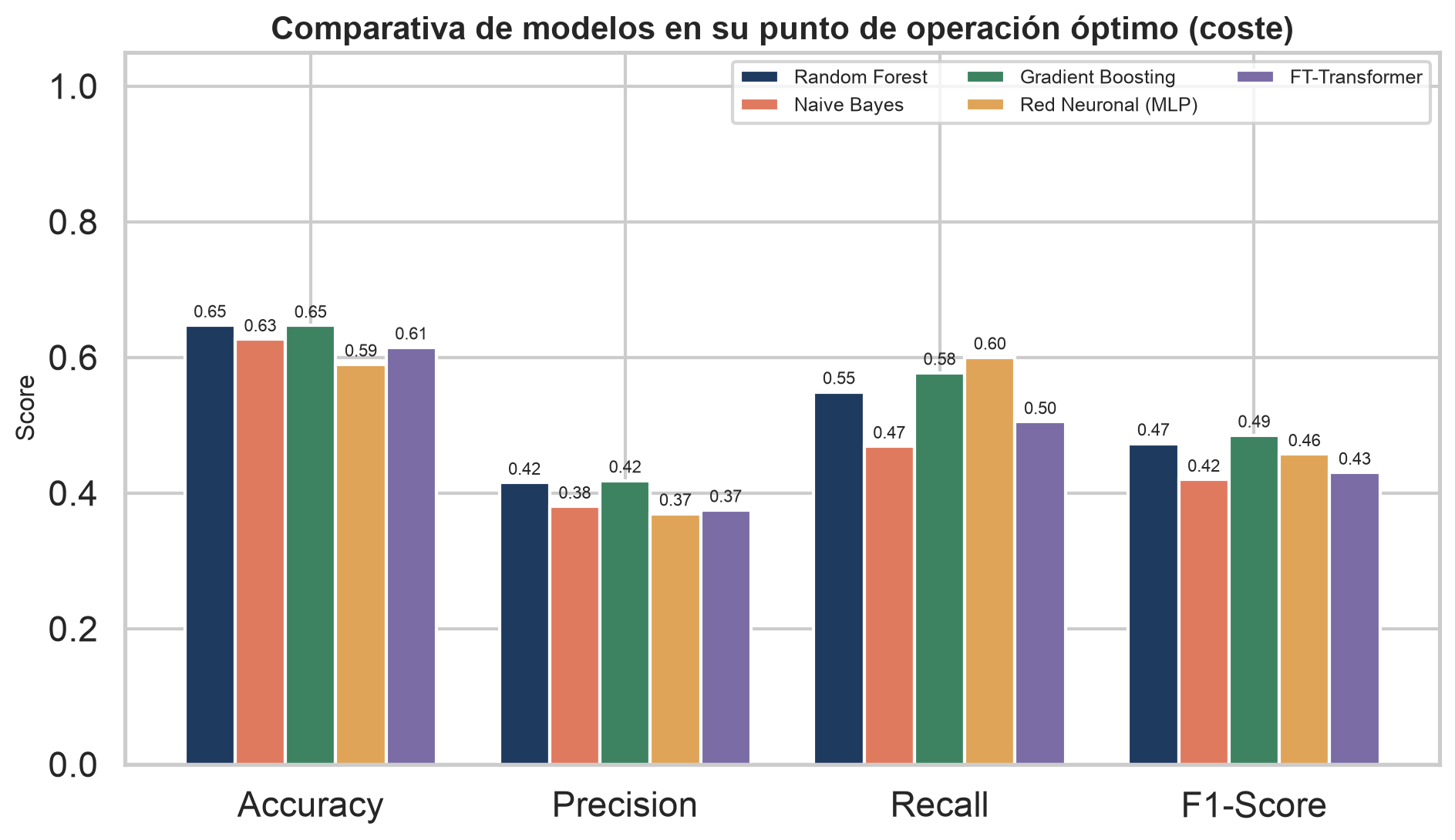
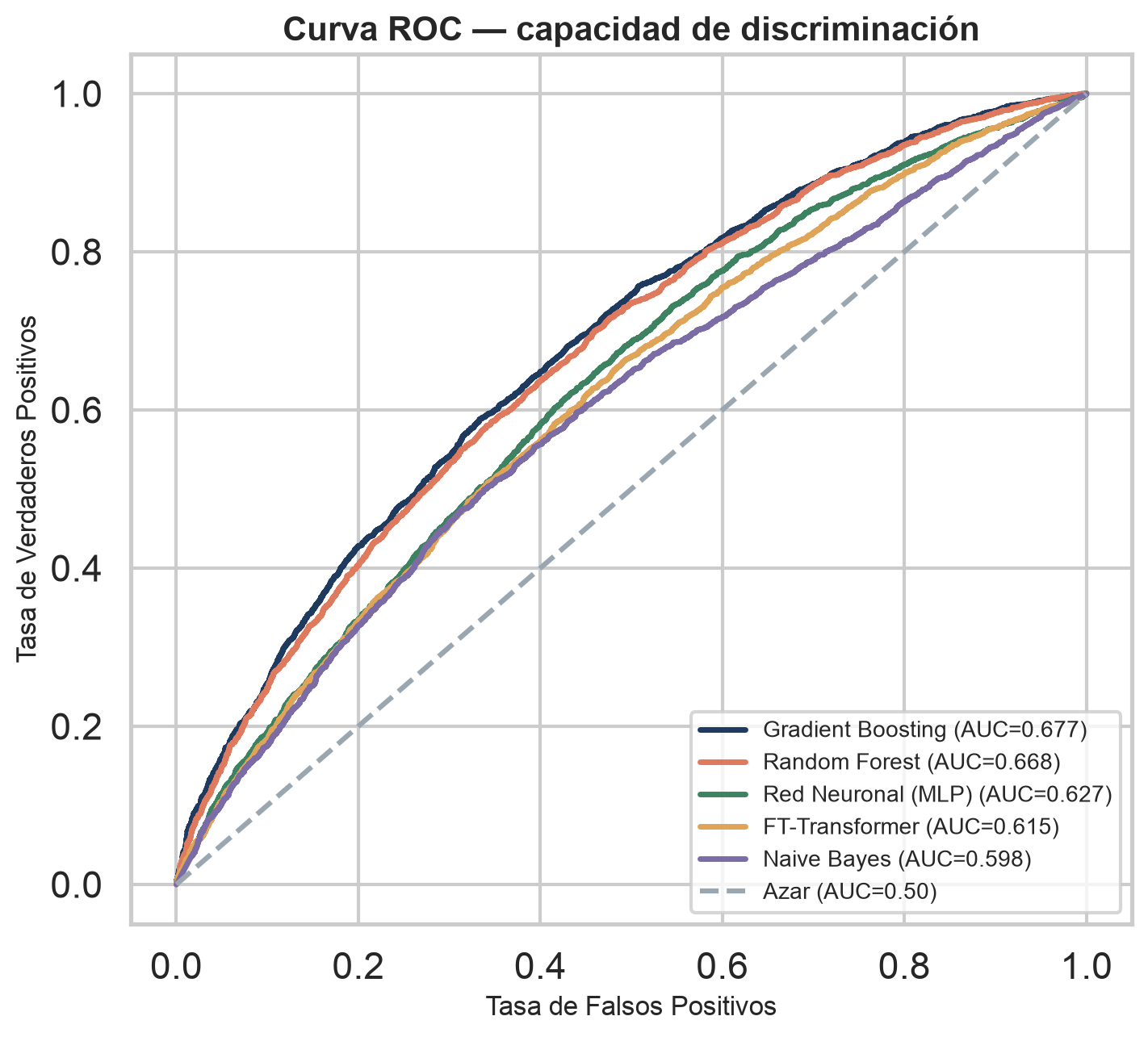
No ganamos por ROC-AUC, ganamos por coste mínimo — el objetivo de negocio real. Cada modelo se evalúa a su propio umbral óptimo.
| Modelo | ROC-AUC | Umbral ópt. | Recall | Precision | F1 | Coste mín. | Ahorro |
|---|---|---|---|---|---|---|---|
| 1Gradient BoostingGanador | 0,677 | 0,31 | 0,58 | 0,42 | 0,485 | €1.192.791 | €53.370 |
| 2Random Forest | 0,668 | 0,32 | 0,55 | 0,42 | 0,47 | €1.196.498 | €49.663 |
| 3Red Neuronal (MLP) | 0,627 | 0,30 | 0,60 | 0,37 | 0,46 | €1.212.997 | €33.163 |
| 4FT-Transformer (deep learning) | 0,615 | 0,32 | 0,50 | 0,37 | 0,43 | €1.215.937 | €30.223 |
| 5Naive Bayes | 0,598 | 0,47 | 0,47 | 0,38 | 0,42 | €1.216.087 | €30.073 |
Ni la Red Neuronal ni el FT-Transformer entrenado sobre los datos superan al Gradient Boosting — un resultado esperado y bien documentado en la literatura. (Se probó primero TabPFN, un transformer tabular preentrenado, pero está gated en HuggingFace y exige token.)
Este es el corazón del proyecto. El umbral no es 0,50 por defecto: es 0,31, el punto que minimiza el coste total esperado. Moverlo transforma el negocio.
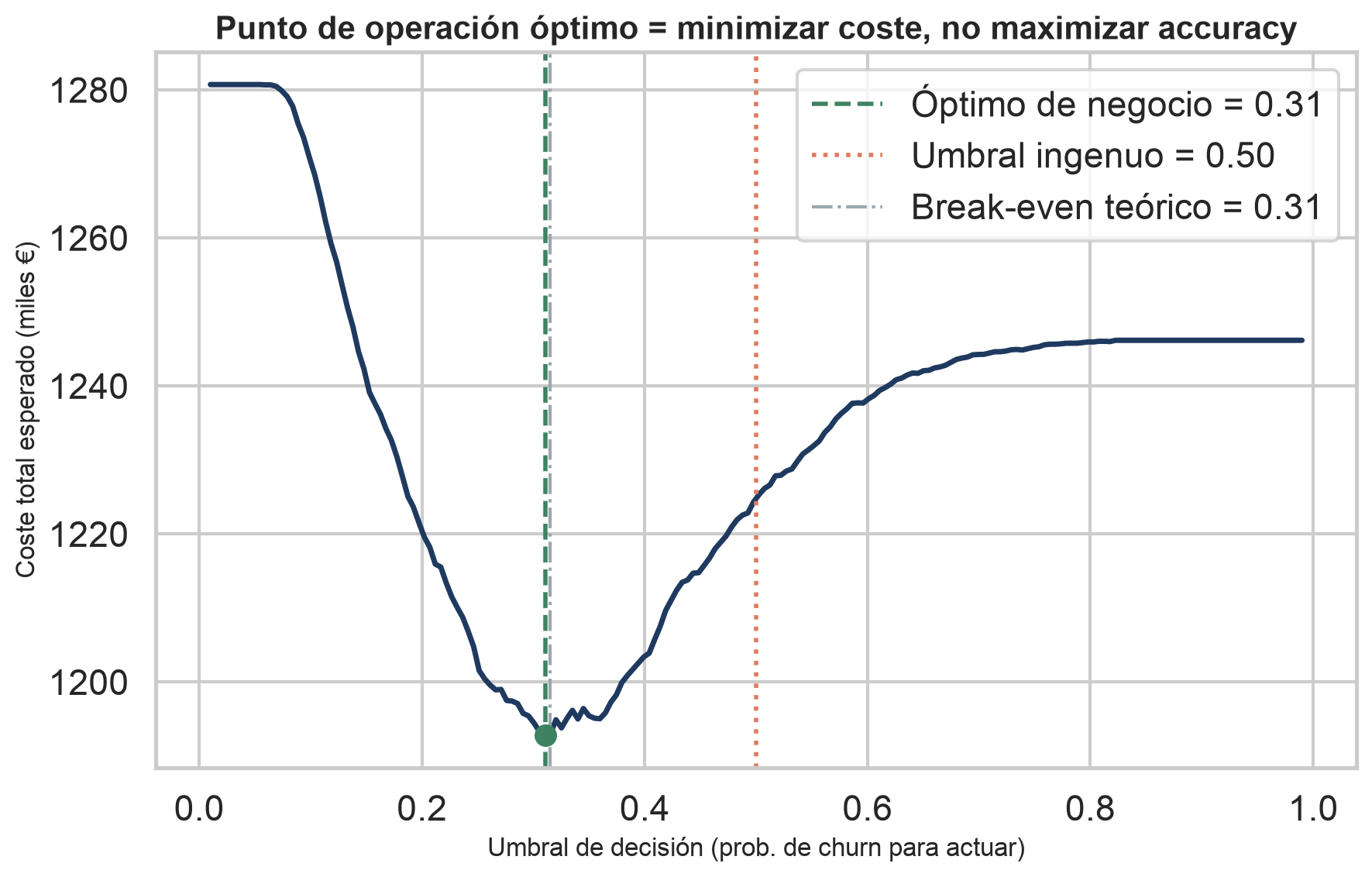
Umbral de operación óptimo, frente al 0,50 por defecto. El break-even teórico (0,315) lo confirma.
Recall de churn. Al bajar el umbral, el modelo pasa de detectar 1 de cada 8 fugas a casi 6 de cada 10.
El desbalance no se corrige reponderando clases, sino moviendo el umbral donde el euro lo pide.
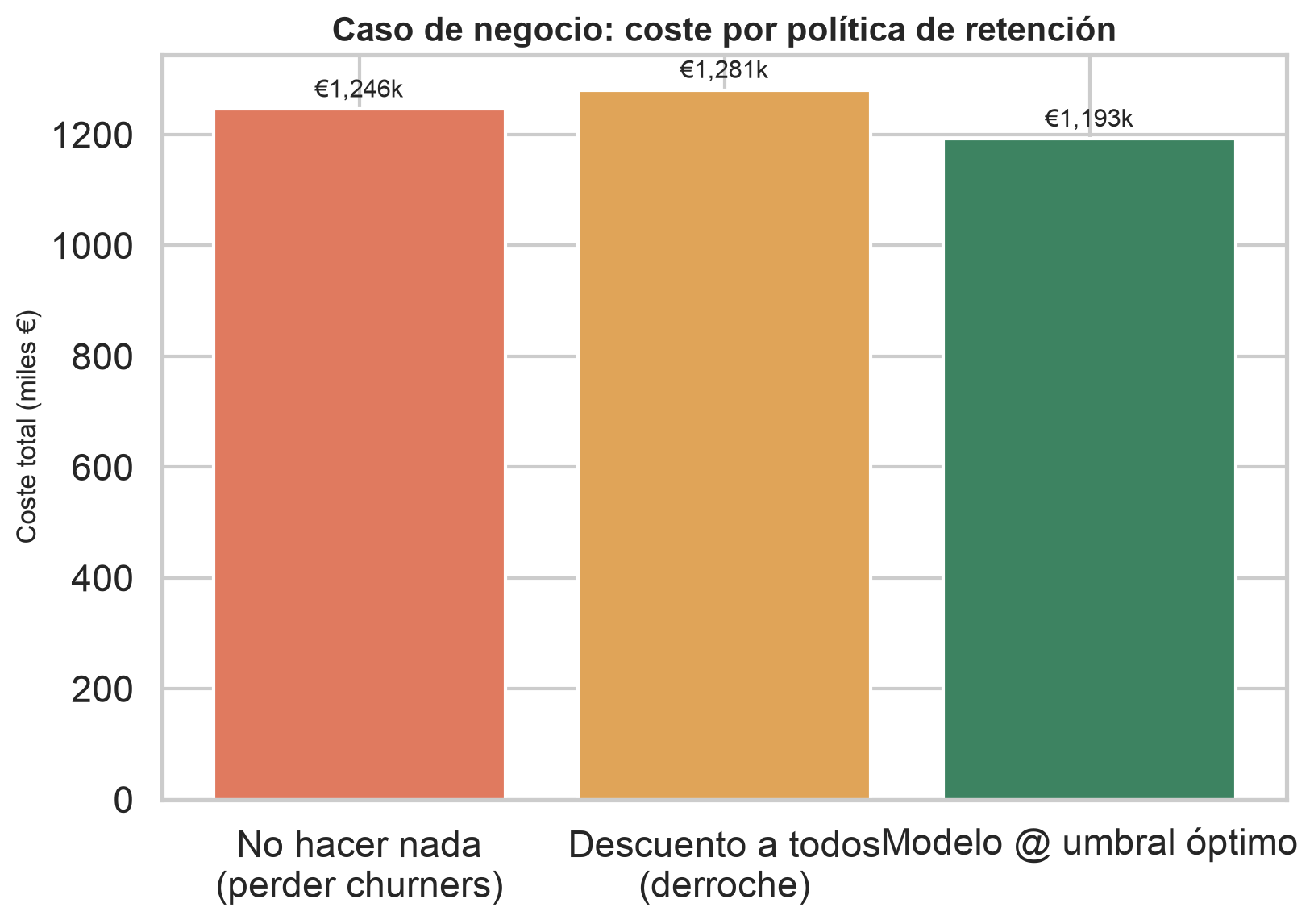
Comparamos el coste total sobre el test de 10.210 clientes. No hacer nada pierde churners; el descuento a todos derrocha margen; el modelo, en su umbral óptimo, gana.
Ahorro vs. no actuar
Ahorro vs. descuento a todos
Ahorro vs. umbral ingenuo 0,5
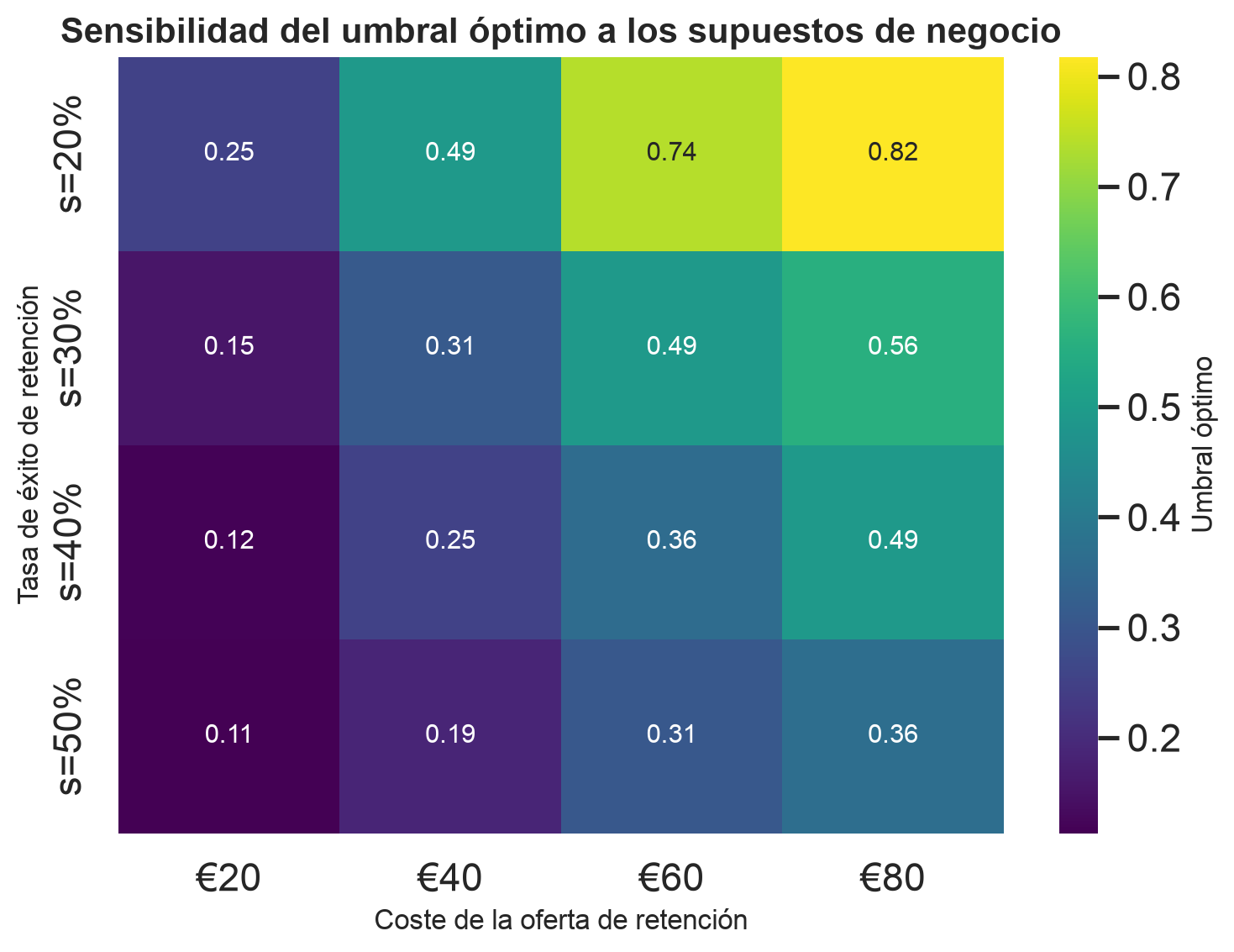
Supuestos económicos (editables por el comité)
Al punto óptimo se marcan 4.060 de 10.210 clientes del test. El cuadrante caro es el Falso Negativo: churners que no vimos venir.
Matriz de confusión al umbral óptimo
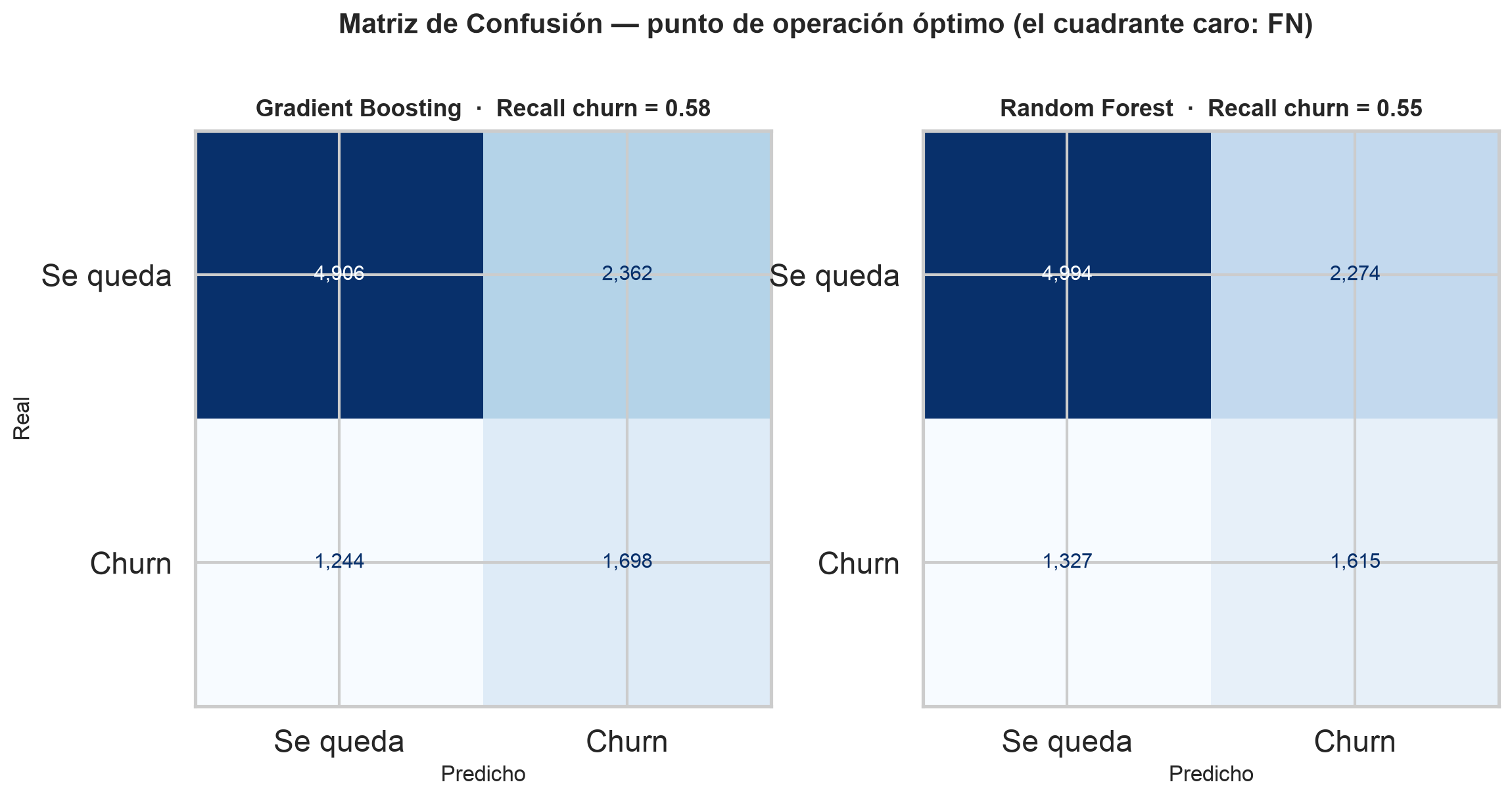
Con un churn del 28,8%, un modelo que prediga "nadie se va" acierta el 71,2% de las veces — y no captura ni un solo churner. La accuracy engaña cuando las clases están desbalanceadas.
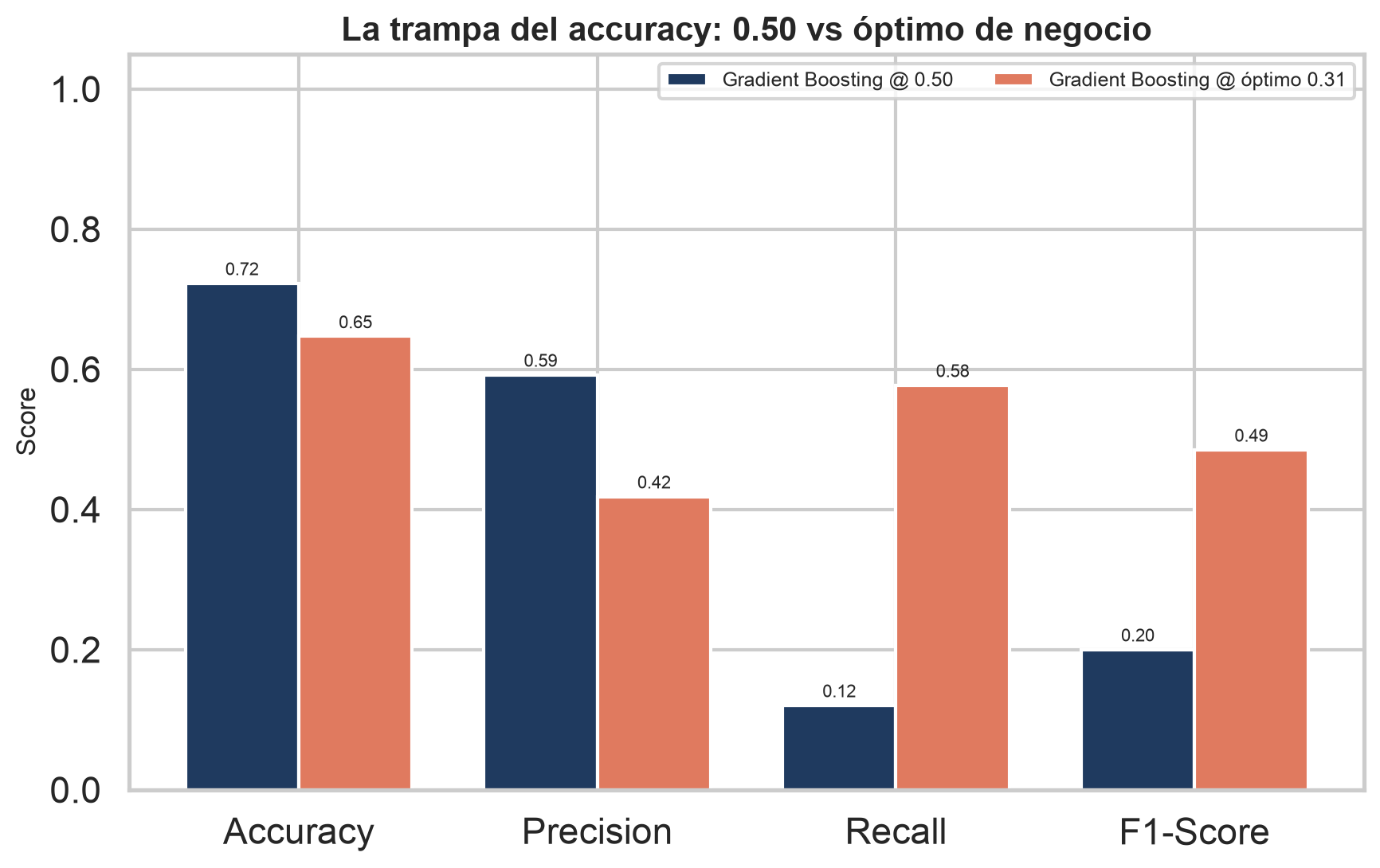
Al umbral 0,50 el Gradient Boosting parece "preciso", pero solo detecta el 12% de los churners. En euros, deja casi toda la fuga sin atender.
Bajando el umbral a 0,31 el recall sube al 58%. Se sacrifica algo de accuracy, pero se rescata el margen que la accuracy ignoraba. Por eso el objetivo es el coste.
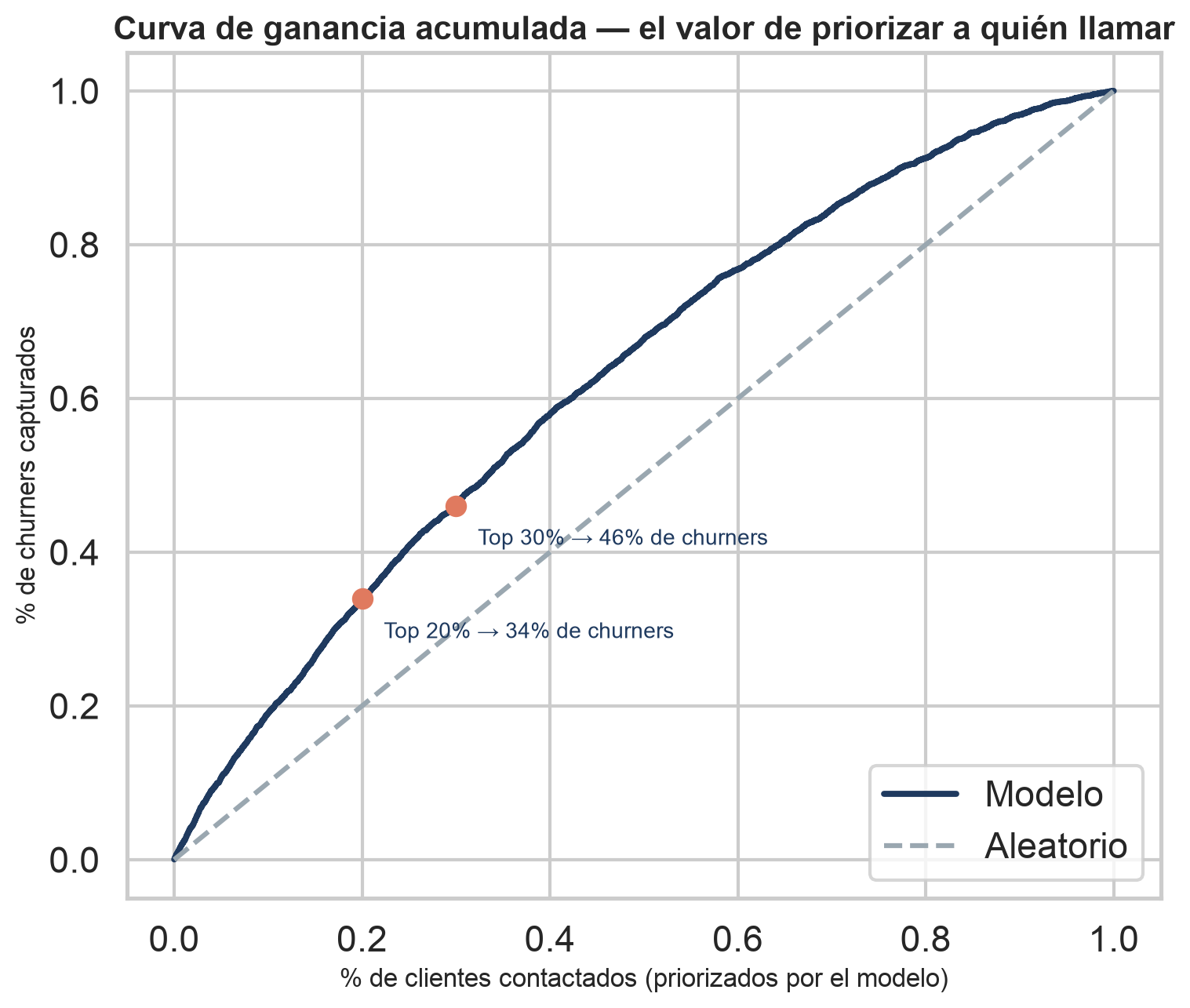
Ordenando a los clientes por su probabilidad de churn, la campaña concentra el esfuerzo donde más rinde. Con un tercio de los contactos se cubre casi la mitad de los churners.
de la base contactada (ordenada por el modelo)
de todos los churners capturados
La curva de ganancia acumulada demuestra que el modelo concentra la señal: prioriza a los clientes de mayor riesgo, permitiendo al equipo de retención gastar el presupuesto donde de verdad evita fugas.
Es la traducción operativa del modelo: una cola priorizada por la que ir bajando hasta agotar el presupuesto disponible.
El modelo ganador puntúa el holdout de 20.000 clientes sin etiqueta y devuelve exactamente a quién llamar. No es un informe: es una cola de trabajo para el equipo de retención.
De la probabilidad a la acción: el equipo recorre los 7.948 priorizados de mayor a menor riesgo, activando ofertas de retención hasta agotar el presupuesto — con un ROI esperado de 1,33x.
Cifras del experimento sobre el dataset público Cell2Cell, no de datos reales de Elastic.
Un buen resultado sin método correcto no es fiable. Estas decisiones garantizan que las cifras son honestas y reproducibles.
Sin class_weight='balanced': la media de probabilidad (0,29) coincide con la tasa real (0,288). El desbalance se gestiona moviendo el umbral (cost-sensitive), no distorsionando las clases.
El coste del falso negativo se calcula sobre el margen de contribución, porque solo el margen es beneficio realmente perdido — no la facturación completa.
La oferta cuesta también cuando el cliente es churner real y solo funciona ~30% de las veces. Eso evita el óptimo degenerado de "llamar a todo el mundo".
Imputación y encoding se ajustan solo en train con Pipeline + ColumnTransformer. El test nunca contamina el aprendizaje.
ServiceArea (747 categorías) se resuelve con frequency encoding, no con un label-encoding arbitrario que inventaría un orden inexistente.
El óptimo se estresa frente a los supuestos económicos: el punto de operación es robusto ante cambios razonables en los costes de FP/FN.